



IA : de l'expérimentation à l'industrialisation ! avec Alexis Berges - Preligens
💡 millefeuille.ai: le media pour comprendre les enjeux de l’IA et les mettre à profit dans notre société et nos métiers — par un collectif d’ingénieurs & d’entrepreneurs français.
Salut à tous !
Aujourd'hui, nous partageons notre conversation avec Alexis Berges, Director of AI Engineering chez Preligens.
🍰 On a adoré aborder les rouages du ML Ops et les enjeux de l’industrialisation de l’IA au sein d’une organisation R&D. On y retient des principes fondamentaux et la nécessité de bien s’acculturer avant de se lancer tête baissée !
Merci beaucoup Alexis pour ton éclairage 👏
Au menu aujourd’hui :
👩🏽🎓 Le parallèle entre le DevOps et le MLOps
🤔 Que choisir entre faire soi même ou choisir des outils parmi une multitude ?
📚 Qu’est-ce que l’industrialisation du développement IA concrètement ?
👥 Quelle type d’organisation choisir pour industrialiser du développement IA ?
👀 Où se renseigner - les sources recommandées par Alexis

Si quelqu’un t’a transféré cette édition et que tu souhaites t’inscrire à millefeuille.ai c’est par ici :
🍰 MF : Qu'est-ce qui fait que l'on ne peut pas appliquer naïvement de l'agile à l'IA?
👉 Alexis :
L'agilité en développement de logiciels a connu une évolution significative au cours des trois ou quatre dernières décennies, mais le paysage a été profondément transformé par l'avènement du mouvement DevOps il y a environ 10 ans. Le DevOps s'est donné pour mission de briser les silos traditionnels entre les équipes de développement (Dev) et d'opérations (Ops), favorisant ainsi une meilleure collaboration et communication entre ces deux entités au sein d'une organisation. Cependant, lorsqu'il s'agit d'appliquer les principes de DevOps au domaine du développement d'intelligence artificielle (IA), plusieurs défis et nuances se présentent. L'un des principaux défis réside dans la nature expérimentale et incertaine du développement d'IA. Contrairement au développement de logiciels classiques, où les exigences sont souvent changeantes, mais quasiment toujours techniquement faisables, les projets d'IA sont caractérisés par des cycles expérimentaux et une incertitude élevée quant aux résultats.
La question fondamentale est de savoir comment faire passer les équipes d’un travail séquentiel -où chaque équipe passe ses réalisations à la suivante - , à une situation où les équipes peuvent travailler en parallèle, en produisant des outils mobilisables par l’équipe en charge de la livraison finale. L'objectif du DevOps est de créer un flux continu de développement, de test et de déploiement, mais dans le contexte de l'IA, les cycles peuvent être plus longs en raison de la collecte et de la préparation de données massives, de l'entraînement de modèles et de l'évaluation. Pour appliquer les principes du DevOps à l'IA, c’est-à-dire mettre en place ce que l’on appelle le MLOps, il est essentiel de comprendre qu’il n’y a pas encore de réponse standardisée, contrairement au DevOps. Il n’est donc pas encore possible d’y trouver une réponse nette dans l’écosystème. Il faut donc rappeler en permanence aux équipes les objectifs de création d’un flux continu de développement, et se donner les moyen de créer des outils ou à minima de la glue entre outils tiers permettant d’enchaîner les étapes de création de l’IA, tout en prenant garde à ne pas réduire l’autonomie des équipes produisant les modèles. Le caractère expérimental de l’IA est la raison pour laquelle on parle de MLOps vs DevOps : cette spécificité demande des suites d’outils différentes pour répondre aux mêmes enjeux macro.
🍰 MF : Faut-il faire ou acheter des outils ML Ops pour aider les équipes à produire de l'IA?
👉 Alexis :
Au-delà des outils, c’est pour moi avant tout une question de culture. En effet, lorsqu'on parle de MLOps, le premier réflexe est souvent de penser aux outils. Et pour cause, le marché est inondé : 39 outils pour la surveillance, 32 pour le déploiement, 31 pour le suivi des expériences, si l’on en croit le recensement fait dans un article récent sur le sujet... La liste est longue. Mais est-ce vraiment la solution pour aider les équipes à produire de l'IA de qualité ?
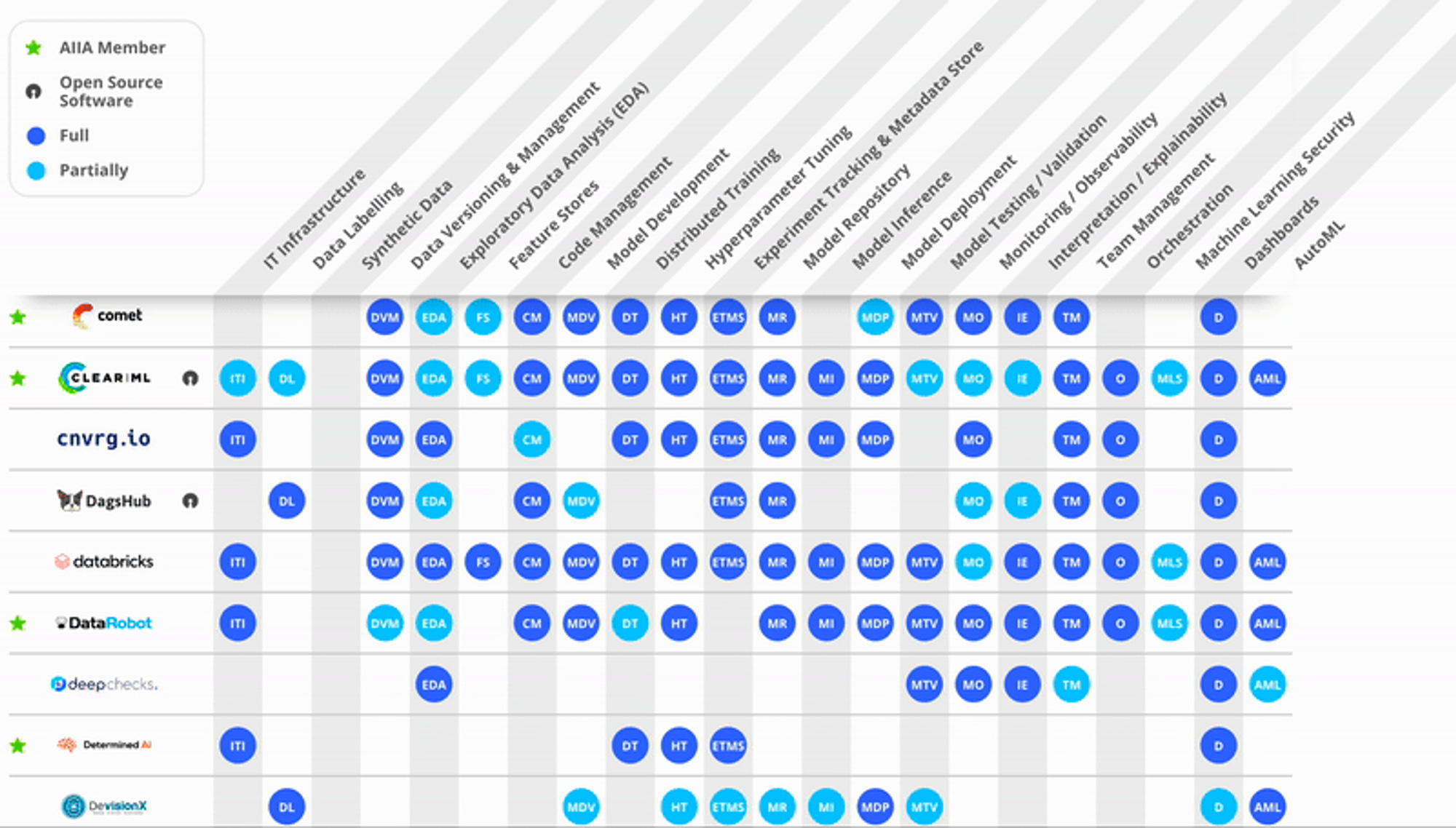
Si l'on regarde de plus près, on se rend compte que la réponse n'est pas si simple. Reprenons l'exemple du DevOps, le grand frère de MLOps. Ce qui a fait le succès du DevOps, ce n'est pas seulement les outils, mais une combinaison de philosophies culturelles, de pratiques et, bien sûr, d'outils.


Aujourd'hui, le MLOps semble être à la croisée des chemins. Beaucoup d'entreprises se jettent sur les outils, espérant que cela résoudra tous leurs problèmes. Mais la réalité est tout autre. Sans une culture MLOps solide, ces outils peuvent même devenir un fardeau.
La prolifération des outils peut entraîner une grande confusion, un manque d’interconnectivité et la fragmentation actuelle de l’outillage donne peu de garanties à la longévité de chacune de ces solutions. Si chaque membre de l'équipe utilise un outil différent ou l'utilise différemment, cela peut rapidement devenir chaotique. Si trop d’outils sont intégrés, l’évolution de la glue maison entre outil deviendra lourde pour intégrer les évolutions de chaque outil. Il est donc nécessaire de bien peser le pour et le contre entre une approche “make” et une approche “buy” sur le MLOps.
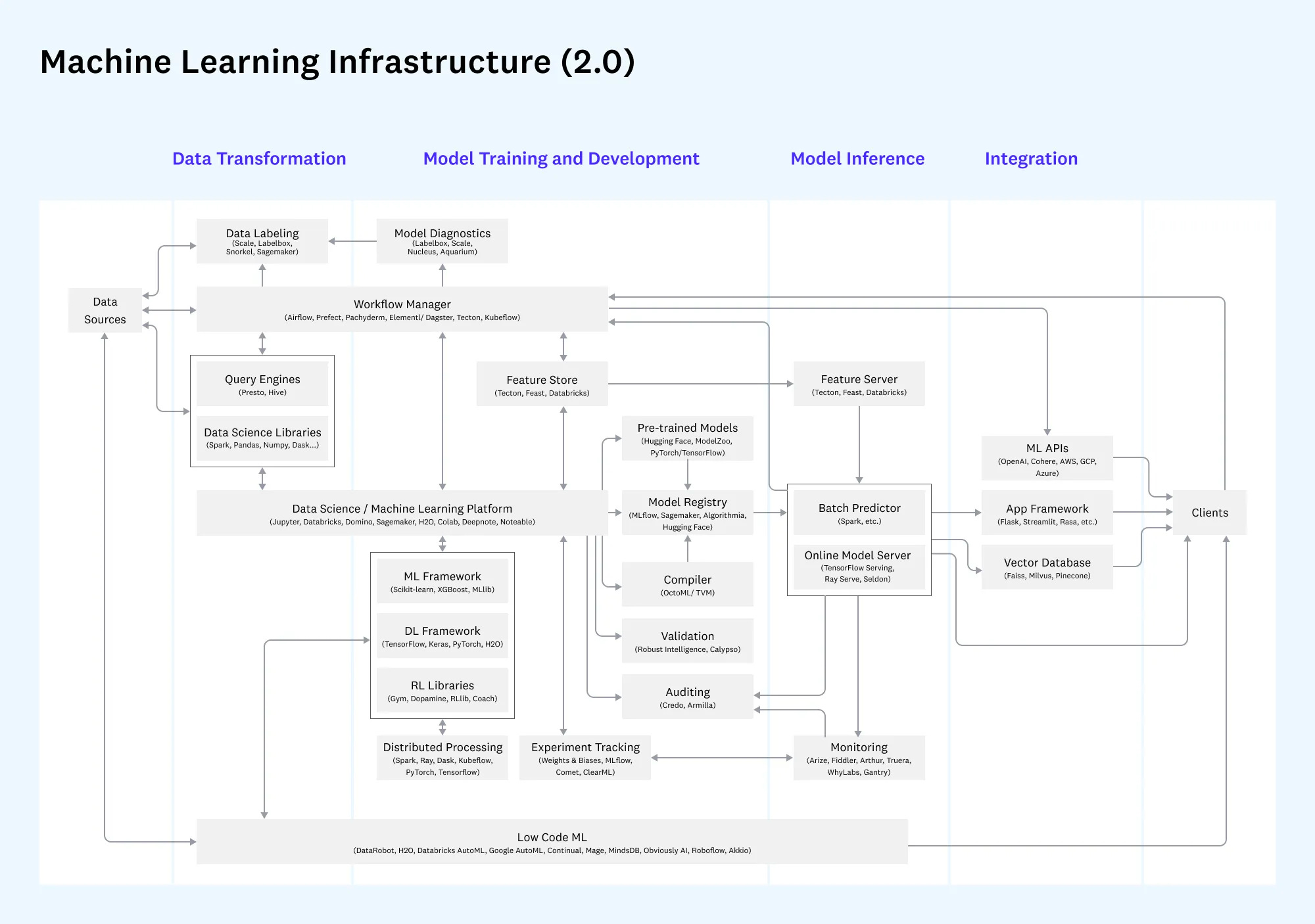
🍰 MF : Qu'est-ce que l'industrialisation dans le contexte de l'IA et quelles sont les nuances à prendre en compte?
👉 Alexis :
Par industrialisation dans le contexte de l’IA, j’entends les différentes étapes, pratiques et outils permettant de passer d’un prototype à une solution pleinement fonctionnelle. Voici comment j’y réfléchis :
Étapes de l'Industrialisation :
Récolte et Nettoyage des Données : Un temps élevé est toujours consacré au nettoyage de données. Il est important de s’outiller et de chercher à optimiser ces étapes, tant pour gagner en efficacité que pour gagner en rétention de Data Scientists, considérant souvent ces tâches comme ingrates.
Développement de l'IA, c’est-à-dire son entraînement à proprement parler : comment réduire le temps humain lié à ces entrainements, comment fournir des environnements d’expérimentation permettant rapidement et facilement de se consacrer au coeur scientifique du problème sans perdre de temps autour.
Déploiement et Packaging : ici, pour déployer un modèle dans un environnement de production (du plus facile, dans le cloud, au plus difficile, on premise sans accès internet), il faut mobiliser des compétences éloignées de celles des Data Scientists. Il est néanmoins -comme évoqué plus haut- important de les responsabiliser et leur permettre de le faire. Il faut alors investir dans une suite d’outils leur permettant d’abstraire ces domaines d’expertise tout en restant maîtres et garant de la livraison chez le client.
Division des Tâches : il est normal de commencer à construire un équipe en recrutant des Data Scientists couteaux suisses. Un des enseignements de la révolution industrielle est que la division du travail permet des gains d’efficacité, il est bien évident que l’IA ne déroge pas à la règle, il convient donc de réfléchir aux domaines d’intervention des uns et des autres, et de penser la suite d’outil de façon à permettre la construction d’expertises sur les différentes sous-étapes.
Éviter les Pièges :
Isolement des Data Scientists : il est essentiel d'éviter que les Data Scientists travaillent en silo, produisant uniquement des notebooks sans se soucier de leur mise en production (moins fréquent ces temps-cis il est vrai, mais très fréquent il y a quelques années). Cela peut conduire à des solutions non optimales ou non utilisables.
Industrialisation à l'Échelle : l'objectif est de s'assurer que les solutions d'IA peuvent fonctionner à grande échelle, gérer de nombreuses inférences et être mises à jour régulièrement.
Quelques nuances sont cependant à considérer. En effet, l'approche d'industrialisation peut varier selon que vous développiez une IA générique utilisée dans de nombreux secteurs ou une solution d'IA spécifique, nécessitant une expertise métier spécifique. Selon le type d'IA, il peut être nécessaire d'intégrer des experts métier dans le processus de développement, en particulier si l'IA nécessite une connaissance approfondie d'un domaine spécifique.
🍰 MF : Comment organiser les équipes de développement d'IA et les faire grandir?
👉 Alexis :
La question de l'organisation et de la croissance des équipes de développement d'IA est cruciale et complexe. Tout comme pour les compétences liées à la data, il faut déterminer s'il est préférable de centraliser ou de décentraliser ces compétences. La réponse dépend de plusieurs facteurs : les priorités de l'entreprise, la taille de l'organisation et les équipes déjà en place. Chaque modèle, qu'il soit centralisé, décentralisé ou même dual (combinant les deux approches), a ses avantages et ses inconvénients.
Chez Preligens, nous nous sommes interrogés sur le modèle de staffing à adopter pour l'IA. Cette réflexion est similaire à celle de décider si l'on doit combiner au sein des mêmes équipes les compétences de développement front-end et back-end ou les séparer. De plus, la stratégie de recrutement doit être adaptée pour attirer des talents ayant une sensibilité à la création d'outils, ce qui soulève d'autres questions organisationnelles.
En réalité, il n'y a pas de réponse unique. Dans un écosystème de 150 à 200 personnes, il est possible d'adopter les deux approches. Cela est bien documenté dans la littérature sur les écosystèmes data, et il en va de même pour l'IA. Une option est de regrouper tous les experts en IA au sein d'une même équipe. Une autre approche consiste à avoir des "feature teams" autonomes du point de vue managérial. Ces équipes peuvent consacrer environ 20% de leur temps à développer une culture commune autour de leur métier, tout en se concentrant principalement sur une fonctionnalité spécifique.
Ici chez Preligens, nous avons opté pour une gestion centralisée par compétence. Bien que cette approche présente des défis managériaux, elle est bénéfique pour renforcer une culture commune.
🍰 MF : merci Alexis ! Est-ce que tu peux nous laisser les sources que tu recommandes pour aller plus loin sur le sujet ?
👉 Alexis :
J’insiste sur le besoin de bien comprendre les enjeux du software et son fonctionnement lorsque l’on veut faire de l’IA en quantité dite industrielle. Je recommande ainsi plusieurs sources :
QQ littératures sur la décentralisation vs centralisation de données : Data Mesh vs Data Fabric
Très belle semaine à tous !
— l’équipe millefeuille.ai
👋 Si tu veux voir la dernière conversation c’est par ici : “De Petit Ours Brun à Voxxx, les prédictions hasardeuses de l’IA” avec Christian Vigne.
Si tu as aimé l’édition, pense à cliquer sur le bouton ❤️ et à laisser un commentaire pour que plus de personnes puissent découvrir millefeuille.ai sur Substack 🙏.
👉 Et c’est par ici pour nous suivre sur Linkedin et Twitter 👈
Super didactique. Merci beaucoup 🙏